
Congratulations to Bandhav for an impactful Ph.D. work. We will miss you!

Models for low-latency, streaming applications could benefit from the knowledge capacity of larger models, but edge devices cannot run these models due to resource constraints. A possible solution is to transfer hints during inference from a large model running remotely to a small model running on-device. However, this incurs a Read More ...
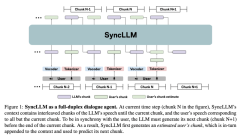
Despite broad interest in modeling spoken dialogue agents, most approaches are inherently half-duplex’’ -- restricted to turn-based interaction with responses requiring explicit prompting by the user or implicit tracking of interruption or silence events. Human dialogue, by contrast, isfull-duplex’’ allowing for rich synchronicity in the form of quick and dynamic Read More ...

Extracting the speech of participants in a conversation amidst interfering speakers and noise presents a challenging problem. In this paper, we introduce the novel task of target conversation extraction, where the goal is to extract the audio of a target conversation based on the speaker embedding of one of its Read More ...

Check out some media coverage of our work: https://www.popsci.com/technology/ai-headphones-noise-cancelling https://www.technologyreview.com/2024/05/23/1092832/noise-canceling-headphones-use-ai-to-let-a-single-voice-through

Check out the project: https://tsh.cs.washington.edu/ In crowded settings, the human brain can focus on speech from a target speaker, given prior knowledge of how they sound. We introduce a novel intelligent hearable system that achieves this capability, enabling target speech hearing to ignore all interfering speech and noise, but the Read More ...
Check out the article: https://www.technologyreview.com/2023/11/09/1083145/noise-canceling-headphones-could-let-you-pick-and-choose-the-sounds-you-want-to-hear/

Imagine being able to listen to the birds chirping in a park without hearing the chatter from other hikers, or being able to block out traffic noise on a busy street while still being able to hear emergency sirens and car honks. We introduce semantic hearing, a novel capability for Read More ...

Imagine being in a crowded room with a cacophony of speakers and having the ability to focus on or remove speech from a specific 2D region. This would require understanding and manipulating an acoustic scene, isolating each speaker, and associating a 2D spatial context with each constituent speech. However, separating Read More ...

Using wind to disperse microfliers that fall like seeds and leaves can help automate large-scale sensor deployments. Here, we present battery-free microfliers that can change shape in mid-air to vary their dispersal distance. We design origami microfliers using bi-stable leaf-out structures and uncover an important property: a simple change in Read More ...

The emergence of water-proof mobile and wearable devices (e.g., Garmin Descent and Apple Watch Ultra) designed for underwater activities like professional scuba diving, opens up opportunities for underwater networking and localization capabilities on these devices. Here, we present the first underwater acoustic positioning system for smart devices. Unlike conventional systems Read More ...

Justin will be joining Carnegie Mellon University as an assistant professor in the School of Computer Science in Software and Societal Systems and in Electrical and Computer Engineering in Fall 2024. Congrats Justin!
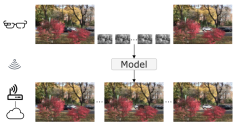
We present NeuriCam, a novel deep learning-based system to achieve video capture from low-power dual-mode IoT camera systems. Our idea is to design a dual-mode camera system where the first mode is low power (1.1 mW) but only outputs grey-scale, low resolution and noisy video and the second mode consumes Read More ...
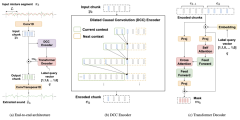
We present the first neural network model to achieve real-time and streaming target sound extraction. To accomplish this,we propose Waveformer, an encoder-decoder architecture witha stack of dilated causal convolution layers as the encoder, anda transformer decoder layer as the decoder. This hybrid archi-tecture uses dilated causal convolutions for processing large Read More ...

The tech giant acquired Sound Life Sciences, a small University of Washington spinout that developed an app to monitor breathing, GeekWire has learned. https://www.geekwire.com/2022/exclusive-google-quietly-acquired-a-seattle-digital-health-startup-that-built-an-app-to-monitor-breathing/ Gollakota founded the company in 2018. Sound Life Sciences’ app monitored breathing using sonar technology to detect movement. The app had the potential to ease the Read More ...

Check out our large effort to helping enable new born hearing screening in Kenya. https://tune.cs.washington.edu/Home.html
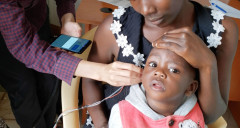
Check out our Nature biomedical engineering paper on detecting otoacoustic emissions using smartphones and earphones and using it for new-born hearing screenin. https://www.nature.com/articles/s41551-022-00947-6

Ex-Ph.D. student, Vikram Iyer, was awarded the SIGMOBILE Doctoral Dissertation Award for “creative and inspiring work that shows how low-power sensing, computing and communication technologies can be used to emulate naturally-occurring biological capabilities.” Congrats Vikram on an inspiring Ph.D. thesis and joining UW CSE as professor Vikram is the third Read More ...

Since its inception, underwater digital acoustic communication has required custom hardware that neither has the economies of scale nor is pervasive. We present the first acoustic system that brings underwater messaging capabilities to existing mobile devices like smartphones and smart watches. Our software-only solution leverages audio sensors, i.e., microphones and Read More ...

Middle ear disorders are one of the most common causes of preventable hearing loss. Unfortunately, while the developing world bears a disproportionate burden of these disorders, it often lacks access to diagnostic tools. Tympanometry is a key test to measure middle ear function, but remains available only on expensive test Read More ...

Plants cover a large fraction of the Earth’s land mass despite most species having limited to no mobility. Many plants have evolved mechanisms to disperse their seeds using the wind. A dandelion seed, for example, can travel as far as a kilometer in dry, windy, and warm conditions. Inspired by Read More ...

Ever taken a phone call in a noisy environment? We built custom earbuds (MobiSys’22) which stream audio from both ears to your phone. We then run a neural net in real-time on the phone, isolating your voice while removing background noise. We also show superior noise suppression than Airpods Pro Read More ...

Frequent prothrombin time (PT) and international normalized ratio (INR) testing is critical for millions of people on lifelong anticoagulation with warfarin. Currently, testing is performed in hospital laboratories or with expensive point-of-care devices limiting the ability to test frequently and affordably. We report a proof-of-concept PT/INR testing system that uses Read More ...
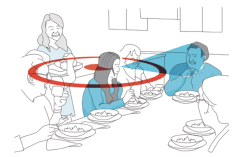
We present DeepBeam, a hybrid model that combines traditional beamformers with a custom lightweight neural network. The former reduces the computational burden of the latter and also improves its generalizability, while the latter is designed to further reduce the memory and computational overhead to enable real-time and low-latency operations. Our Read More ...

https://www.geekwire.com/2019/meet-hacker-professor-whos-saving-lives-smart-devices-sonar/

Anran presents his work on using white noise to track infant breathing on smart speakers. Vikram presents his work on living IoT which is a light weight wireless platform for living insects. https://www.sigmobile.org/mobicom/2019/

Check out our work on monitoring infants using white noise. https://dl.acm.org/citation.cfm?id=3345453

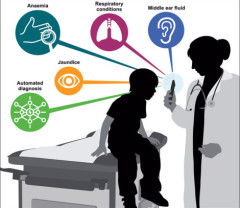
Check out Justin’s Lancent article: https://www.thelancet.com/journals/lancet/article/PIIS0140-6736(19)32087-2/fulltext

Cornell Tech today announced four new professors who will join the campus’ distinguished faculty. With research and industry experience in fields such as machine learning, computational photography, and mobile health applications, these professors will build on Cornell Tech’s interdisciplinary and groundbreaking research. Rajalakshmi Nandakumar, Ph.D., Assistant Professor joins the Jacobs Read More ...

Check out our Digital Medicine paper on detecting cardiac arrest using smart speakers and phones. https://www.nature.com/articles/s41746-019-0128-7

https://www.npr.org/sections/health-shots/2019/05/15/723595540/a-smartphone-app-and-a-paper-funnel-could-help-parents-diagnose-kids-ear-infecti
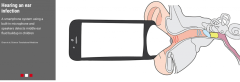


Check out the article written by our friends at Sleepscore and ResMed to the American Academic of Sleep Medicine. http://jcsm.aasm.org/ViewAbstract.aspx?pid=31480&fbclid=IwAR3ybOU44i2J3dcNBXvI3vfllrOrNcPJXUya8AMNL1mLYJ55deBiw7AJaeg

Check out Rajalakshmi’s interview on Science Friday! Rajalakshmi talks about the lab’s work on using active sonar for various applications.
Check out our work on opioid overdose detection using smartphones https://www.technologyreview.com/s/612733/opioid-overdoses-could-be-prevented-by-an-app-that-listens-to-breathing/ https://www.scientificamerican.com/article/new-app-uses-sonar-to-detect-opioid-overdoses/ https://www.cnbc.com/2019/01/07/this-cellphone-app-can-detect-an-opioid-overdose-and-save-your-life.html

Check out our multi-year effort that culminated into the Science Translational Medicine paper published in 2019 http://stm.sciencemag.org/content/11/474/eaau8914

Check out the coverage of the Living IoT program on NBC News. https://www.nbcnews.com/mach/science/how-tiny-backpacks-are-turning-bees-living-drones-ncna948046


https://www.eetimes.com/document.asp?doc_id=1333985&page_number=3&fbclid=IwAR1ghr5-0uEQ7EUjdJqqXL3-rNcVKB9C4WGT_-wikUnhuA0iELAv1Ymw5yQ

Congrats to Rajalakshmi and Vikram. Check out the work at https://homes.cs.washington.edu/~gshyam/Papers/ulocate.pdf

https://www.cnbc.com/2018/11/02/about-the-weight-of-a-toothpick-first-wireless-robo-insect-takes-off.html “Because the laser alone can’t provide enough voltage to move the wings, the team designed a circuit that boosts the 7 volts coming out of the photovoltaic cell up to the 240 volts needed for flight. To give RoboFly control over its own wings, the engineers added a Read More ...

“LoRa Backscatter: Enabling The Vision of Ubiquitous Connectivity”, published in the Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies is the winner of an IMWUT Vol. 1 Distinguished Paper Award. A selection committee made of 14 members of the IMWUT Editorial Board (see list below) selected – Read More ...

To quote Colin Lawler: “Starting with the last question – smartphones have improved both in terms of processing capability and speaker and microphone quality. When combining this with a revolutionary.and patented, new approach to sonar, we found a way to enable a pretty clear picture of the respiratory pattern and Read More ...


Check out out UIST work on wireless analytics for 3D printed objects https://www.technologyreview.com/the-download/612255/3d-printed-plastic-objects-can-track-their-own-use-without-any-electronics/ http://printedanalytics.cs.washington.edu/wireless-analytics-3d.pdf



Rajalakshmi Nandakumar has been recognized with a Paul Baran Young Scholar Award from the Marconi Society for her work on mobile apps capable of detecting potentially life-threatening health issues. She is the first Allen School student to receive the award, which honors outstanding early-career researchers in wireless communications and the Read More ...

https://www.doctoroz.com/episode/oz-investigates-could-eating-more-salt-actually-save-your-life?video_id=5797590614001 Fitness trainer Gunnar Peterson and Dr. Oz explain how the SleepScore app can help you get more rest. This technology is based on the ApneaApp technology licensed from our lab.

The UW team behind ApneaApp, left to right: Nate Watson, Rajalakshmi Nandakumar, and Shyam Gollakota. Photo credit: Sarah McQuate/University of Washington More than a billion people worldwide experience problems related to sleep, which can have a significant impact on their health, productivity, and overall quality of life. In the Read More ...


Check out the paper: https://homes.cs.washington.edu/~gshyam/Papers/videobackscatter.pdf Check out the article by Techcrunch: https://techcrunch.com/2018/04/19/technique-to-beam-hd-video-with-99-percent-less-power-could-sharpen-the-eyes-of-smart-homes/

Wired covers our work on charging smartphones using lasers. https://www.wired.com/story/wireless-charging-with-lasers/

Although mobile devices such as tablets and smartphones let us communicate, work and access information wirelessly, their batteries must still be charged by plugging them in to an outlet. But we have for the first time developed a method to safely charge a smartphone wirelessly using a laser. http://laserpower.cs.washington.edu/

Scientific American covers our work on data storage using magnetized fabric with a great title. https://www.scientificamerican.com/article/how-many-gigs-are-you-wearing/
Vikram is one of ten MSR Ph.D. fellows of 2018. https://www.microsoft.com/en-us/research/academic-program/phd-fellowship-program/

https://www.seattletimes.com/seattle-news/education/no-batteries-wires-or-plugs-uw-team-makes-plastic-devices-that-communicate-via-wi-fi/ and others
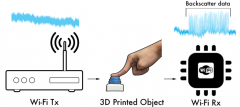
Check out our Siggraph work on 3D printing wireless connected objects. http://printedwifi.cs.washington.edu/

A shirt that doubles as your password? UW researchers creating ‘high-tech’ fabrics http://komonews.com/news/local/uw-researchers-creating-high-tech-fabrics-that-can-store-data
“This smart fabric doesn’t need electronics or batteries, but it can encode data readable by a magnetometer like the one in your phone.” https://www.technologyreview.com/s/609264/your-next-password-may-be-stored-in-your-shirt-cuff/

Checkout coverage of our long range backscatter system on Economist. https://www.economist.com/news/science-and-technology/21728866-long-range-frugal-new-chip-could-be-just-what-smart-city-needs-clever-way Also check out other coverage: https://spectrum.ieee.org/tech-talk/telecom/wireless/lowpower-sensors-use-backscatter-to-transmit-data-several-kilometers

Our recent work on LoRa backscatter breaks the long held belief that backscatter is a short-range communication system. http://longrange.cs.washington.edu/

With TVM, researchers and practitioners in industry and academia will be able to quickly and easily deploy deep learning applications on a wide range of systems, including mobile phones, embedded devices, and low-power specialized chips — and do so without sacrificing battery power or speed. Learn more about this project: Read More ...

Smart devices and appliances are becoming increasingly prevalent, but as a consequence of adding these connected devices such as smart TVs, phones, and hubs like the Amazon Echo to our homes, there are an increased number of connected speakers and microphones with access to our private environment. In this Read More ...


Check out our work on using music as a surveillance tool. This work is to appear at Ubicomp 2017. http://musicattacks.cs.washington.edu/

Check it out! http://money.cnn.com/video/technology/2017/07/10/battery-free-cell-phone-university-of-washington.cnnmoney/index.html

Check out the first battery-free phone designed by our lab. http://batteryfreephone.cs.washington.edu/

Tom Anderson is elected to the American Academy of Arts and Sciences Allen School’s Tom Anderson elected to the American Academy of Arts & Sciences

Shyam was awarded the Sigmobile Rockstar award. https://news.cs.washington.edu/2017/03/23/allen-schools-shyam-gollakota-wins-2017-sigmobile-rockstar-award/

This project enables connectivity on everyday objects by transforming them into FM radio stations. To do this, we show for the first time that ambient FM radio signals can be used as a signal source for backscatter communication. Our design creates backscatter transmissions that can be decoded on any FM receiver Read More ...

Check out our work on connected cities and smart fabrics. http://www.washington.edu/news/2017/03/01/singing-posters-and-talking-shirts-uw-engineers-turn-everyday-objects-into-fm-radio-stations/


Money Inc. names interscatter and ambient backscatter as two of ten technology inventions of 2016! http://moneyinc.com/top-10-technological-inventions-2016/

Interscatter is being featured in the “Incredible Works Here” ad campaign by Challenge Seattle. This includes various print and bus ads, and even this cookie from their launch event. Check out the website for more details: http://www.incredibleworkshere.com/

Shyam talked about our work on the Internet of Disposable Things at EmTech 2016. https://www.technologyreview.com/s/602630/this-contact-lens-will-kick-start-the-internet-of-disposable-things/?utm_campaign=internal&utm_medium=readnext&utm_source=item_1

Madrona Awards the Madrona Prize to our Backscatter work. http://www.madrona.com/madrona-awards-madrona-prize-backscatter-team-uw-industrial-affiliates-day/ “2016 marks the 11th year of the Madrona Prize which is awarded to a ground breaking and commercially viable technology developed at the University of Washington. Since Madrona’s inception, more than two decades ago, Madrona has funded 16 companies Read More ...
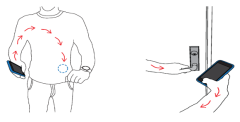
We show for the first time that commodity devices can be used to generate wireless data transmissions that are confined to the human body. Specifically, we show that commodity input devices such as fingerprint sensors and touchpads can be used to transmit information to only wireless receivers that are in Read More ...
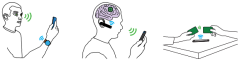
We introduce inter-technology backscatter (Interscatter), a novel approach that transforms wireless transmissions from one technology to another, on the air. Specifically, we show for the first time that Bluetooth transmissions can be used to create Wi-Fi and ZigBee-compatible signals using backscatter communication. Since Bluetooth, Wi-Fi and ZigBee radios are widely Read More ...

FingerIO is a novel fine-grained finger tracking solution that transforms any space around off-the-shelf smartphones or smartwatches into an interactive surfaces. FingerIO does not require instrumenting the finger with sensors and works even in the presence of occlusions between the finger and the device. We achieve this by transforming the Read More ...
We introduce Passive Wi-Fi that demonstrates for the first time that one can generate 802.11b transmissions using backscatter communication, while consuming 3 – 4 orders of magnitude lower power than existing Wi-Fi chipsets. Passive Wi-Fi transmissions can be decoded on any Wi-Fi device including routers, mobile phones and tablets. Building Read More ...

Quoting the article “Now researchers at the University of Washington have found a way to eliminate the airtime and the hassle—by using the human body as a conduit for passing security codes from one device to another. By holding a smartphone in one hand, for example, and touching a doorknob Read More ...

We show for the first time that commodity devices can be used to generate wireless data transmissions that are confined to the human body. Specifically, we show that commodity input devices such as fingerprint sensors and touchpads can be used to transmit information to only wireless receivers that are in Read More ...

The article says Shyam Gollakota uncovered a way to create Wi-Fi signals without radio transistors. And here’s the real payoff: These “passive Wi-Fi” devices use 10,000 times less power than a typical Wi-Fi chip, and 1,000 times less power than the most efficient Bluetooth, thereby significantly reducing the need Read More ...

We introduce inter-technology backscatter (Interscatter), a novel approach that transforms wireless transmissions from one technology to another, on the air. Specifically, we show for the first time that Bluetooth transmissions can be used to create Wi-Fi and ZigBee-compatible signals using backscatter communication. Since Bluetooth, Wi-Fi and ZigBee radios are widely Read More ...

FingerIO is a novel fine-grained finger tracking solution that transforms any space around off-the-shelf smartphones or smartwatches into an interactive surfaces. The work got an honorable mention award at CHI 2016.

Check out the coverage on our first Wi-Fi enabled contact lens prototype. https://www.technologyreview.com/s/602035/first-wi-fi-enabled-smart-contact-lens-prototype/

Passive Wi-Fi captured the Best Paper Award at the 13th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’16) Congratulations to the team
FingerIO is a novel fine-grained finger tracking solution that transforms any space around off-the-shelf smartphones or smartwatches into an interactive surfaces. The work got an honorable mention award at CHI 2016. Check out the project website

Shyam Gollakota was selected by CNN Money as one of five innovators who are changing the world for a recent segment called Visionaries 2020.

Passive Wi-Fi, a new low-power Wi-Fi communications system developed by the team, has been named one of MIT Technology Review’s 10 Breakthrough Technologies of 2016. The system, which can generate Wi-Fi transmissions using 10,000 times less power than conventional methods, was developed in UW CSE professor Shyam Gollakota’s Networks & Read More ...

Power over Wi-Fi named a top innovation of 2015 by Popular Science Find more about the project
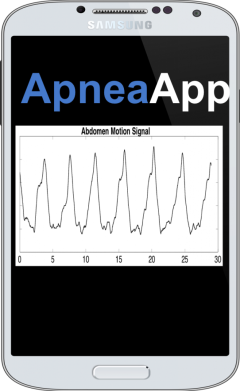
Sleep apnea is a common medical disorder that is estimated to affect more than 18 million American adults and is linked to attention deficit/hyperactivity disorder, high blood pressure, diabetes, heart attack, stroke, and increased motor vehicle accidents. ApneaApp is a contactless solution for detecting sleep apnea events by monitoring the Read More ...

University of Washington Interim President Ana Mari Cauce has announced the appointment of 17 new members to the university’s prestigious CoMotion Presidential Innovation Fellows program.
Our work on Power over WiFi is covered by BBC, Wired, Tech Review and others. Find more information about the power over WiFi system.



Wi-Fi Imaging Check out the project: http://homes.cs.washington.edu/~gshyam/Papers/wision.pdf>Project Paper


Tom Anderson’s Operating Systems book With Mike Dahlin is the bestseller OS book on Amazon!

MIT Tech Review link ” The technology could free engineers to extend the tendrils of the Internet and computers into corners of the world they don’t currently reach. Battery-free devices that can communicate could make it much cheaper and easier to widely deploy sensors inside homes to take control of Read More ...

RF-powered computers are small devices that compute and communicate using only the power that they harvest from RF signals. While existing technologies have harvested power from ambient RF sources (e.g., TV broadcasts), they require a dedicated gateway (like an RFID reader) for Internet connectivity. We present Wi-Fi Backscatter, a novel Read More ...

Our work that is to appear at MOBICOM 2014 introduces the first design that enables an instantaneous feedback channel on battery-free backscatter devices. Specifically, it gives receivers a way to provide low-rate feedback to the transmitter on the same frequency as that of the backscatter transmissions, using neither multiple antennas Read More ...
This year’s USENIX Software Tools Award has been presented to Tom Anderson and his colleagues Mic Bowman, David Culler, Larry Peterson, and Mothy Roscoe for the creation of PlanetLab. https://www.usenix.org/about/stug


Two papers from the networks lab will appear at APSys in Beijing in June Machine Fault Tolerance for Reliable Datacenter Systems by Danyang, Qiao, Dan, Arvind, and Tom and User scripting on Android using BladeDroid by Ravi, Dominic, Pingyang, Ray, Will, and Mike You can see the full program on Read More ...


People with tetraplegia have either partially or completely lost their abilities to move their arms or legs. We want technologies to help those patients to interact with their surroundings. Fortunately, many of those patients are able to move their tongues on command. Researchers have thus asked if it is possible Read More ...
We will be presenting the following work at SIGCOMM 2014 Turbocharging Backscatter Communication Aaron Parks, Angli Liu, Shyam Gollakota, and Josh Smith Connecting RF-Powered Things to the Internet Bryce Kellogg, Aaron Parks, Shyam Gollakota, Josh Smith, and David Wetherall One tunnel is enough Simon Peter, Umar Javed, Qiao Zhang, Doug Read More ...

Vincent and Vamsi win QualComm Innovation Fellowship 2014 for ambient backscatter. Here is the information: http://www.qualcomm.com/research/university-relations/innovation-fellowship/2014

Existing gesture-recognition systems consume significant power and computational resources that limit how they may be used in low-end devices. We introduce AllSee, the first gesture-recognition system that can operate on a range of computing devices including those with no batteries. AllSee consumes three to four orders of magnitude lower power Read More ...


Check out the reddit article where Will answers questions Reddit article where Will discusses teaching in North Korea

Check out our work on non-invasive Tongue Machine Interface at CHI 2014 Non-Invasive Tongue Machine Interface Qiao Zhang, Shyam Gollakota, Ben Taskar, and Raj Rao

Check out the following UW papers at NSDI 2014 Bringing Gesture Recognition to All Devices Bryce Kellogg, Vamsi Talla, and Shyam Gollakota How Speedy is SPDY? Sophia Wang, Aruna Balasubramanian, Arvind Krishnamurthy, and David Wetherall

uProxy is a browser extension that lets users share alternative more secure routes to the Internet. It’s like a personalised VPN service that you set up for yourself and your friends. uProxy helps users protect each other from third parties who may try to watch, block, or redirect users’ Internet Read More ...

Strong User Isolation for Scalable Web Applications PDF Web applications are a frequent target of successful attacks. The damage is amplified by the fact that application code is responsible for security enforcement in most web frameworks. In this paper we design and implement Radiatus, a web framework where all application-specific Read More ...

WiSee was awarded the best paper at MobiCom 2013. Check out the project webpage: wisee.cs.washington.edu


As computing devices become smaller and more numerous, powering them becomes more difficult; wires are often not feasible, and batteries add weight, bulk, cost, and require recharging/replacement that is impractical at large scales. Ambient backscatter communication solves this problem by leveraging existing TV and cellular transmissions, rather than generating their Read More ...
Ambient Backscatter wins the best paper award at ACM SIGCOMM 2013, to be held in Hong Kong, China between August 12 and August 16, 2013. The paper is titled Ambient Backscatter: Wireless Communication Out of Thin Air Check out the UW CSE announcement and the project webpage.
Check out the papers from UW at MOBICOM 2013. Whole-Home Gesture Recognition Using Wireless Signals, Qifan Pu, Sidhant Gupta, Shyam Gollakota, and Shwetak Patel Interference Alignment Using Motion, Fadel Adib, Swarun Kumar, Omar Aryan, Shyam Gollakota, and Dina Katabi QuickSync: Accelerating Information Transfer Over Unsynchronized Screen-Camera Links, Wenjun Hu, Hao Read More ...

WiSee is the first whole-home gesture recognition system using wireless signals. Since wireless signals do not require line-of-sight and can traverse through walls, WiSee can enable whole-home gesture recognition using few wireless sources (e.g., a Wi-Fi router and a few mobile devices in the living room). Our results show that Read More ...

Technology trends and economic forces are moving us toward a world in which personal information is valuable, and companies have an incentive to obtain as much of it as possible. Targeted advertising, for example, has revolutionized revenue generation, but while this is good for companies, the implications for user privacy Read More ...

Vincent Liu and Tom Anderson were quoted in an article on F10 in the UW Daily! You can read the article at http://dailyuw.com/archive/2013/05/08/science/uw-researchers-fix-faults-online-networks

UW CSE professor Shyam Gollakota has received the 2012 ACM Doctoral Dissertation Award – presented annually to the author of the best doctoral dissertation, worldwide, in computer science – for his MIT doctoral dissertation “Embracing Interference in Wireless Systems.” Read more at UW CSE News
Congratulations to UW students, faculty, and alumni for the excellent research and systems we built that are to appear in SIGCOMM 2013! Ambient Backscatter: Wireless Communication out of Thin Air Vincent Liu, Aaron Parks, Vamsi Talla, Shyam Gollakota, David Wetherall, Josh Smith Bringing Cross-Layer MIMO to Today’s Wireless LANs Swarun Read More ...
WProf is a tool that extracts dependencies of activities during a page load. For Web developers, WProf can help identify the bottleneck activities of your Web pages. For browser architects, WProf can relate page load bottlenecks to either Web standards or browser implementation choices.

A large contingent of the UW networks lab was present at NSDI this week. It was great to interact with the community and see the alumni from the lab enjoying their new homes.

Congratulations to Vincent Liu, Daniel Halperin, Arvind Krishnamurthy and Tom Anderson! "F10: A Fault-Tolerant Engineered Network" was recognized with a Best Paper award at NSDI. UW CSE News » CSE faculty and students win 2013 NSDI “Best Paper” Award NSDI – the USENIX Symposium on Networked Systems Design and Implementation Read More ...

We’re looking forward to presenting a couple of papers at HotOS in May. From the Networking Lab: Arrakis: A Case for the End of the Empire Simon Peter and Thomas Anderson, University of Washington The Case for Onloading Continuous High-Datarate Perception to the Phone Seungyeop Han, University of Washington; Matthai Read More ...

We propose to build a tool, Triceratops, for securing mobile applications. It allows any user to protect his or her personal information from malicious mobile apps, in ways that are not possible today. Triceratops takes a mobile app with a set of security policies as input, and generates a secured Read More ...

Networks Lab members stayed up last night to surprise our Systems Lab Colleagues. Raymond Cheng originally shared this post: Hello Systems Lab!

Arrakis is a new operating system that is designed around recent application and hardware trends: Applications are becoming so complex that they are miniature operating systems in their own right and are fighting with already established OS services. For example, a web browser needs to protect itself against untrusted scripts Read More ...
Coming soon, this will become the official Networks lab website. Our previous web presence didn’t do a good job of highlighting all the awesome projects we're working on.

The UW Introduction to Networking class on Coursera has started up. If you want to learn more about computer networks – or have missed David Wetherall’s sultry voice – this is the class to take! https://www.coursera.org/course/comnetworks
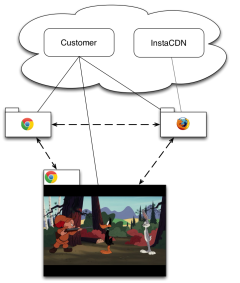
A New Baseline for the Web Free web services often face growing pains. In the current client-server access model, the cost of providing a service increases with its popularity. This leads organizations that want to provide services free-of-charge to rely to donations, advertisements, or mergers with larger companies to cope Read More ...

Blocking-Resistant Network Services The desire for uncensored access to the Internet has motivated the development of both open proxies like Tor and social graph-based overlays like FreeNet. However, neither design is sufficient, as relays in open proxies are easily exposed and blocked, and overlays based just on social trust suffer Read More ...