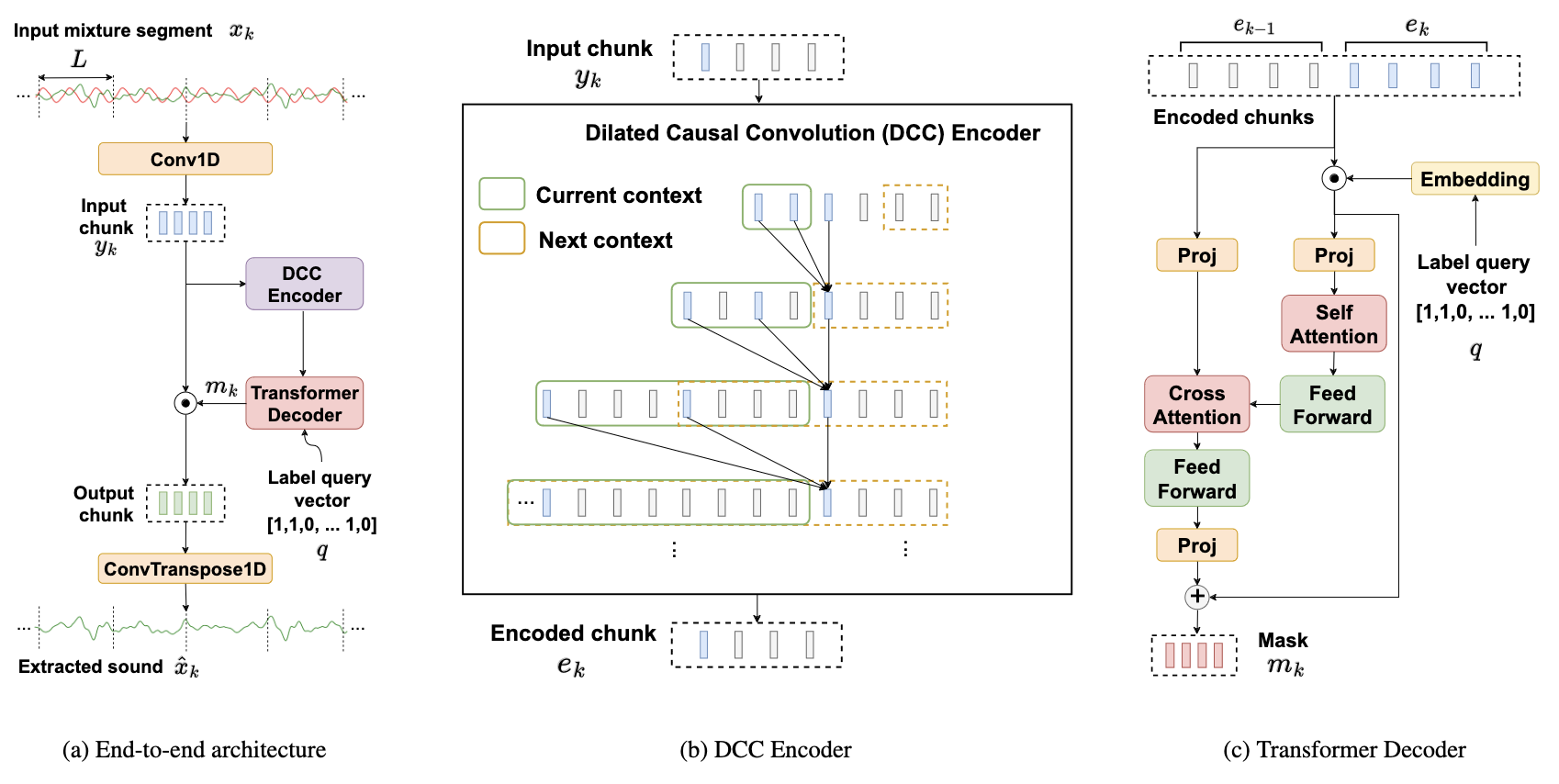
We present the first neural network model to achieve real-
time and streaming target sound extraction. To accomplish this,
we propose Waveformer, an encoder-decoder architecture with
a stack of dilated causal convolution layers as the encoder, and
a transformer decoder layer as the decoder. This hybrid archi-
tecture uses dilated causal convolutions for processing large re-
ceptive fields in a computationally efficient manner, while also
leveraging the generalization performance of transformer-based
architectures. Our evaluations show as much as 2.2–3.3 dB im-
provement in SI-SNRi compared to the prior models for this
task while having a 1.2–4x smaller model size and a 1.5–2x
lower runtime.
We provide code, dataset, and audio samples:
https://waveformer.cs.washington.edu/.